Kontingenční tabulky představují způsob, jak ze spousty detailních informací získat souhrnný přehled. Kontingenční tabulky nám, řečeno manažerskou terminologií, umožňují „přes stromy vidět les“.
Představme si na chvíli, že provozujeme řetězec supermarketů s celorepublikovou působností. Abychom lépe podchytili zvyky našich zákazníků, zavedli jsme věrnostní systém, kdy zákazník dobrovolně poskytne o sobě a své rodině určité osobní údaje – za odměnu získává za každý zaevidovaný nákup body, které mu umožňují čerpat zajímavé slevy a využívat výhodné akce.
Řekněme, že jsme časem vybudovali databázi zákazníků, která vypadá zhruba následovně:
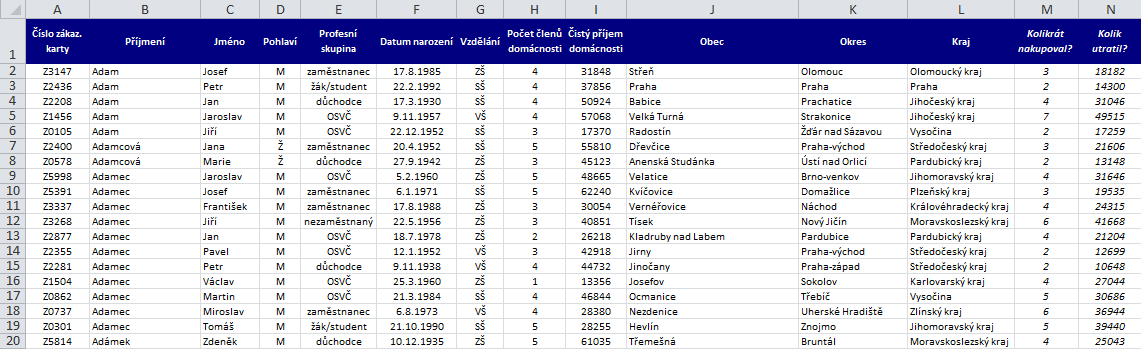
Chceme nyní z této databáze získávat různé souhrnné údaje – jednak z provozních důvodů, jednak pro marketingové účely. V prvé řadě nás může třeba zajímat, kolik máme v každém kraji zákazníků.
Možná vás napadne, že k takovému zjišťování by stačily automatické filtry nebo souhrny, a asi budete mít pravdu. Tyto nástroje se ale hodí ke zjišťováním typu „zobraz jména zákazníků v kraji XXX“. Co když nás v roli manažera ale nezajímají konkrétní lidé, nýbrž jen souhrnné počty?
Použití automatického filtru by znamenalo filtrovat postupně jeden kraj za druhým a psát si někde bokem počty záznamů vyhovujících aktuálnímu filtru. Použití souhrnů by vyžadovalo data různým způsobem třídit a vkládat do tabulky mezisoučty. Elegantní řešení našeho problému představují právě kontingenční tabulky.
Kontingenční tabulky nám umožňují různými způsoby pohlížet na zdrojová data a volbou vhodného nastavení zobrazovat informace, které momentálně potřebujeme zjistit. Zdrojovými daty přitom nemusí být nutně jen tabulky v Excelu, ale třeba i databáze Accessu, SQL Serveru či datových skladech OLAP. Excel se dokáže celkem snadno na takovéto databáze „připojit“ a použít je jako zdroj dat pro kontingenční tabulky.
Vytvoření jednoduché kontingenční tabulky
Na adrese: K:\ProŽáky\Bečvářová Silvie\Podklady\EXCEL si stáhněte soubor KT.xls.Ve staženém souboru je ukázková tabulka zákazníků obsahující několik tisíc záznamů.
Nyní použijeme list Zákazníci obsahující zdrojová data, která chceme analyzovat. Z těchto dat vytvoříme kontingenční tabulku, jež nám dá odpověď na naši první otázku, tj. kolik máme v každém kraji zákazníků.
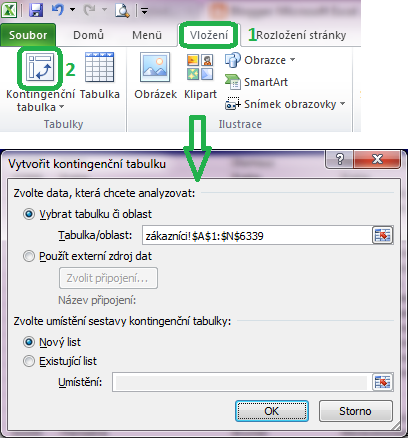
Postup vytvoření kontingenční tabulky je následující:
- Předpokládáme, že zdrojová data jsou umístěna ve formě standardního Excelovského seznamu, tj. v prvním řádku jsou popisky sloupců, v dalších pak data. V datech by neměly být prázdné řádky (jednotlivé buňky samozřejmě prázdné být mohou).
- Vybereme kurzorem nebo klepneme myší někde do tabulky zdrojových dat. Je jedno, kde konkrétně v tabulce budeme mít kurzor – podstatné je, aby byla aktivní jediná buňka.
- Na pásu karet Vložení klepneme na příkaz Kontingenční tabulka (je hned vlevo).
- Objeví se dialogové okno, v němž můžeme vybrat oblast zdrojových dat a umístění, kam se má kontingenční tabulka vložit – viz. obrázek.
- Jelikož jsme v prvním kroku umístili kurzor uvnitř tabulky, měl by Excel poznat sám, kde se nachází oblast zdrojových dat.
- Kontingenční tabulky se většinou umisťují na nový list (protože na stávajícím nebývá dost místa), takže nám stačí v tomto dialogovém okně klepnout na tlačítko OK.
V tuto chvíli bych se ještě rád zmínil, že z jedné zdrojové tabulky můžeme výše uvedeným postupem vytvořit více kontingenčních tabulek – podle toho, jaké souhrny zrovna potřebujeme zjišťovat.
Výše uvedený postup by měl v aktivním sešitě vytvořit nový list vypadající zhruba následovně:
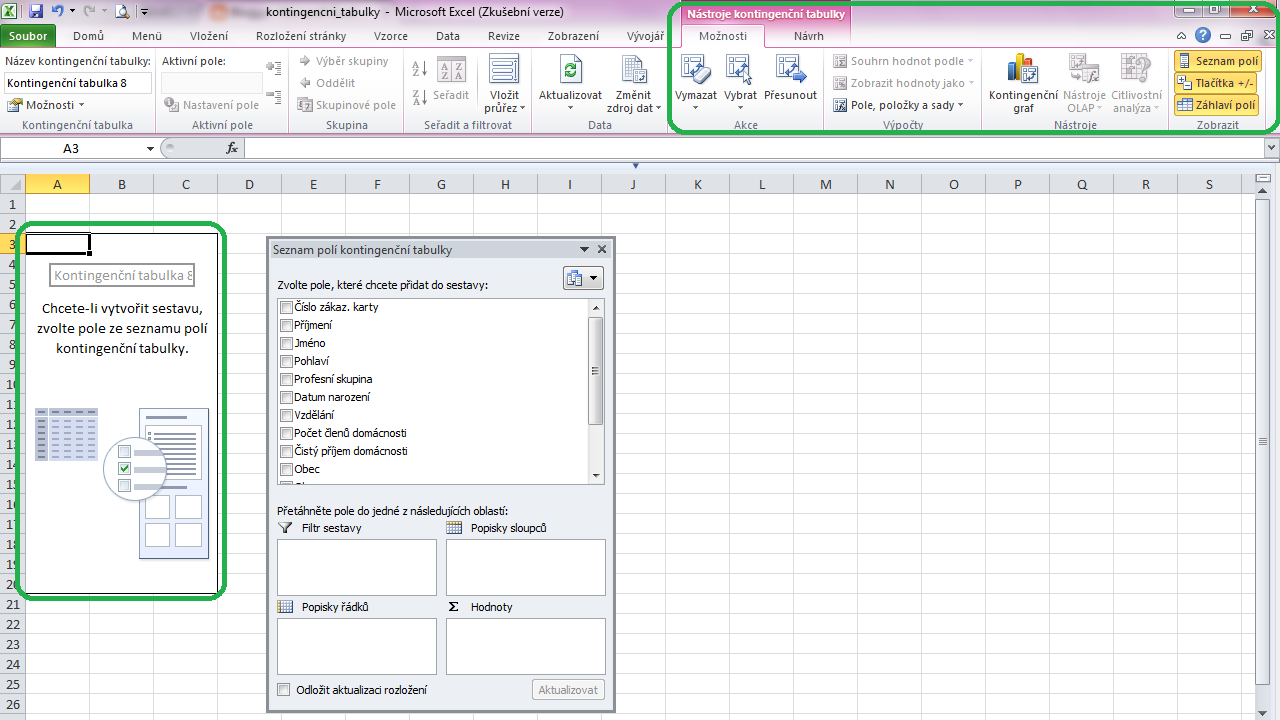
V levé části vidíme prázdnou kontingenční tabulku, vedle ní pak Seznam polí kontingenční tabulky. Všimněte si, že na pásu karet přibyla nová sekce obsahující Nástroje kontingenční tabulky. Pokud bychom klepli myší mimo kontingenční tabulku, seznam polí i nabídka nástrojů zmizí – stačí ale opět klepnout do kontingenční tabulky a měly by se zase objevit.
Věnujme se nyní hlavně Seznamu polí kontingenční tabulky. Jeho okno je rozděleno do pěti částí – v samotném seznamu vidíte názvy jednotlivých polí, které odpovídají popiskům jednotlivých sloupců zdrojové tabulky našich zákazníků. Kromě toho v okně vidíme Pole hodnot, Popisky řádků, Popisky sloupců a Filtr sestavy (v Excelu 2003 nazývaný Stránkové pole).
Vytvářet kontingenční tabulku znamená umisťovat názvy jednotlivých polí v horní části okna do příslušných polí kontingenční tabulky (tj. buď do pole hodnot, nebo popisku řádků či sloupců, nebo do filtru sestavy) – podle toho se automaticky vytváří a aktualizuje vzhled kontingenční tabulky. Tato činnost se nejlépe provádí myší – požadované položky přetahujeme dle potřeby z jedné sekce do druhé – viz obrázek.
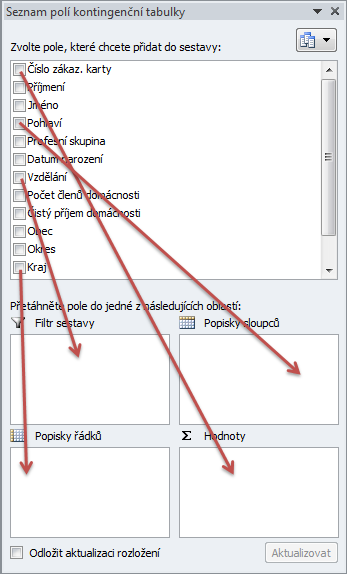
Pole hodnot
Nejdůležitější je tzv. pole hodnot – do něj přetahujeme položky, které chceme spočíst, sečíst či zprůměrovat. Zajímají-li nás počty zákazníků, stačí do pole hodnot přetáhnout položku Číslo zák. karty (může to ale být i jakákoliv jiná „textová“ položka, například příjmení zákazníka). Výsledkem by měla být následující kontingenční tabulka:
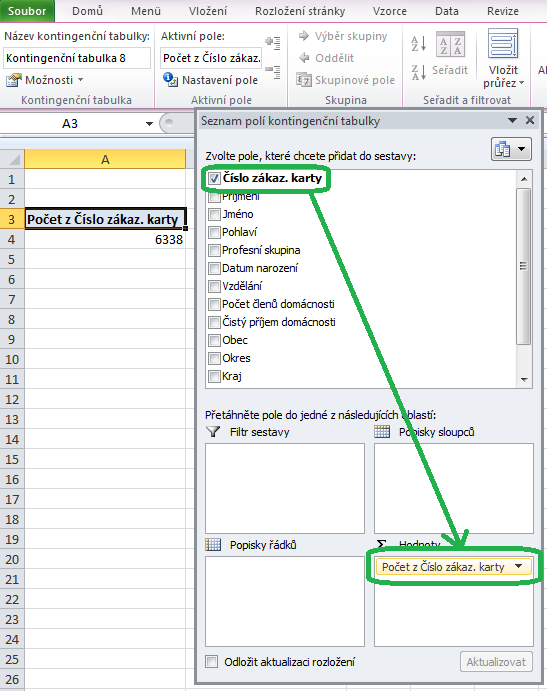
Získali jsme tak první údaj o zákaznících – vidíme, že je jich celkem 6338. Přetažením čísla zákaznické karty (což je popisek prvního sloupce v našem zdroji dat) do pole hodnot se Excel pokusil údaje v tomto sloupci zdrojových dat sumarizovat – a jelikož s textovými údaji (čísla zákaznických karet jsou ve tvaru Z1234) se toho moc napočítat nedá, zobrazil nám jejich počet.
Nyní se pokusíme ten vzdálený pohled, který nám dává informaci o celkovém počtu zákazníků, přiblížit tak, abychom byli schopni zobrazit počty zákazníků na úrovni jednotlivých krajů. Nebo řečeno jinak, chceme rozdělit počet 6338 zákazníků mezi jednotlivé kraje.
Popisky řádků, sloupců
Kritéria, podle nichž chceme záznamy v poli hodnot rozdělit, umisťujeme většinou do popisků řádků nebo do popisků sloupců. Nás zajímá v tuto chvíli jediné kritérium – Kraj – a proto přetáhneme ze seznamu polí položku Kraj do popisků řádků. Výsledek by měl být následující:
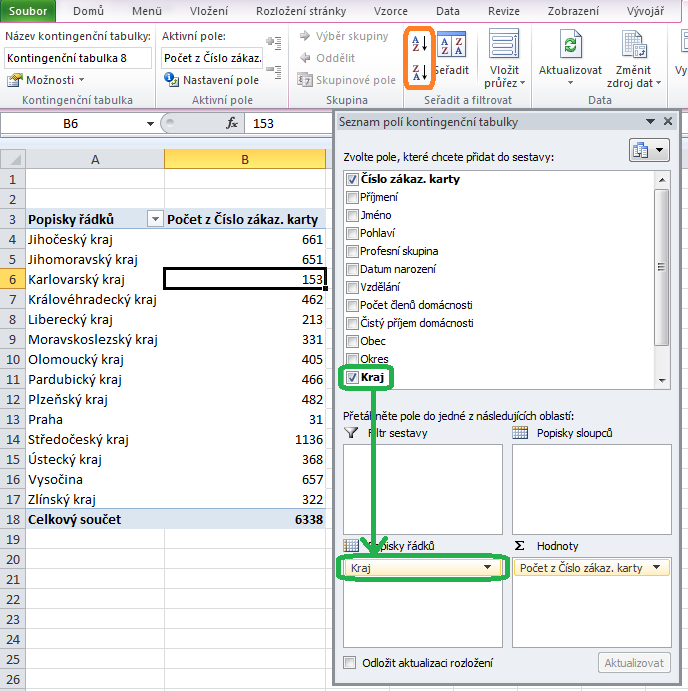
Tím jsme našli odpověď na otázku, kolik máme v každém kraji zákazníků. K výše uvedenému postupu několik poznámek:
- Chceme-li kraje seřadit podle počtu zákazníků (zatím jsou řazeny abecedně), stačí klepnout myší do příslušného sloupce kontingenční tabulky (v našem případě do druhého sloupce, kde jsou počty zákazníků) a použít tlačítka pro řazení na pásu karet – viz obrázek výše.
- Pokud bychom chtěli zjišťovat počty zákazníků v jednotlivých okresech, stačilo by pole Kraj vymazat z popisků řádků (buď ho jednoduše přetáhneme myší pryč z pole popisků řádků nebo zrušíme jeho zaškrtnutí v seznamu polí) a místo něj do popisků řádků vložit pole Okres.
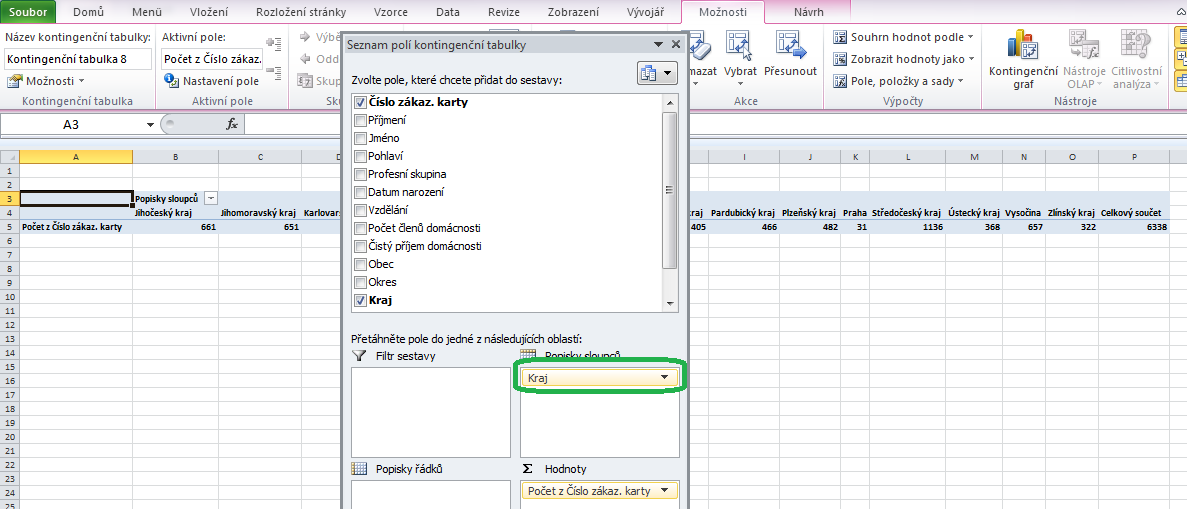
- Co by se stalo, kdybychom pole Kraj nebo Okres neumístili do popisků řádků, ale do popisků sloupců? Kontingenční tabulka by vypadala podobně, jen by nebyla orientovaná svisle, ale vodorovně – čísla by byla stejná, jen by tabulka byla méně přehledná (viz obrázek). Funkčně tedy mezi popisky řádků a popisky sloupců rozdíly nejsou, jde pouze o přehlednost.
Kontingenční tabulka s více kritérii
Zatím to jsme vytvářeli tabulky, které umožňovaly získat přehled o údajích ve zdrojové tabulce podle jediného kritéria – teď si ukážeme, jak lze vytvořit přehled podle více kritérií.
Začneme s ukázkovou databází zákazníků obchodního řetězce, kterou najdete ve stažené tabulce na listu Zákazníci. V první části jsme si ukázali, jak vytvořit kontingenční tabulku, z níž zjistíme počty zákazníků v jednotlivých krajích. Do pole hodnot jsme přetáhli Číslo zákaznické karty, do popisků řádků jsme přetáhli položku Kraj, a kontingenční tabulka vypadala následovně:
Dejme tomu, že nás nyní zajímá nejen kolik máme v kterém kraji zákazníků, ale také, kolik je mezi nimi mužů a kolik je mezi nimi žen. Asi vás napadne, že do kontingenční tabulky přetáhneme položku Pohlaví – ale kam?
Zkusme ji nejprve přetáhnout do popisků řádků pod položku Kraj – výsledek bude vypadat asi takto:
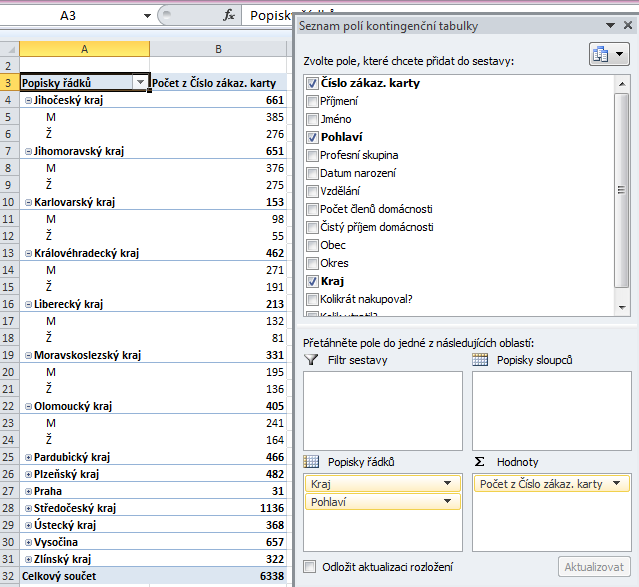
Jak vidíte, data v kontingenční tabulce jsou nyní uspořádána ve dvou hierarchických úrovních. Na vnější úrovni máme celkové počty zákazníků dle jednotlivých krajů, na vnitřní úrovni pak počty mužů a žen v rámci každého kraje. Pomocí tlačítka nalevo od názvu kraje můžeme jednotlivé úrovně dle potřeby rozbalovat a sbalovat – na obrázku výše jsem prvních 7 krajů ponechal rozbalených, zbytek krajů sbalil.
Co by se stalo, kdybychom položku Pohlaví ponechali v popiscích řádků, ale přetáhli ji nad položku Kraj? Prohodily by se pouze úrovně seskupení, takže kontingenční tabulka by nyní vypadala následovně:
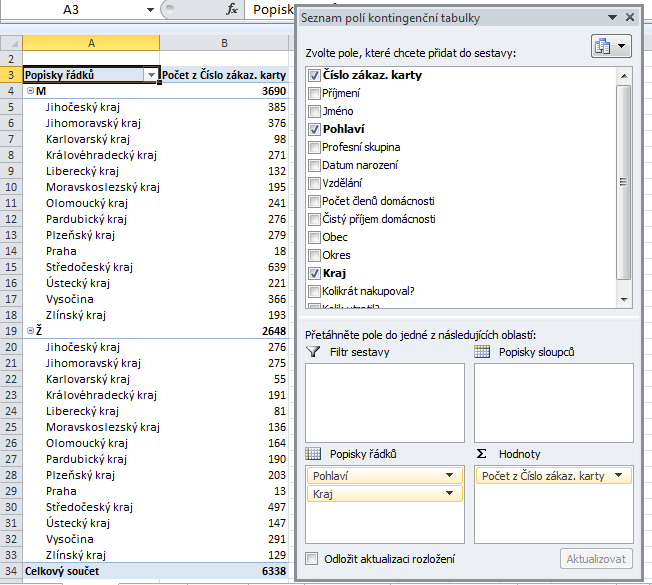
Vyzkoušejme nyní další možnost – pole Pohlaví přesuneme z popisků řádků do popisků sloupců. Kontingenční tabulka pak získá následující tvar:
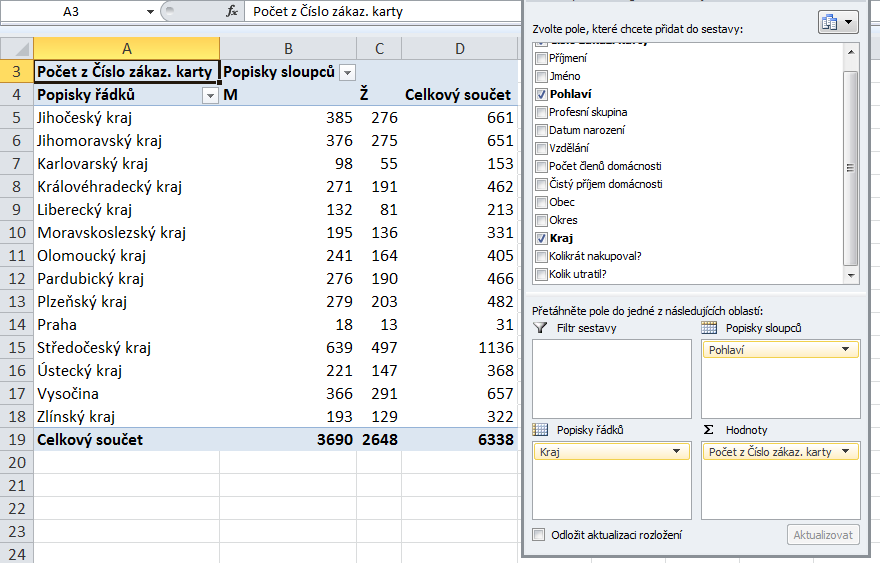
Pro zajímavost ještě ukážu, jak by vypadalo „prohození“ řádků a sloupců, tj. kdybych měl v popiscích řádků Pohlaví a v popiscích sloupců Kraj:
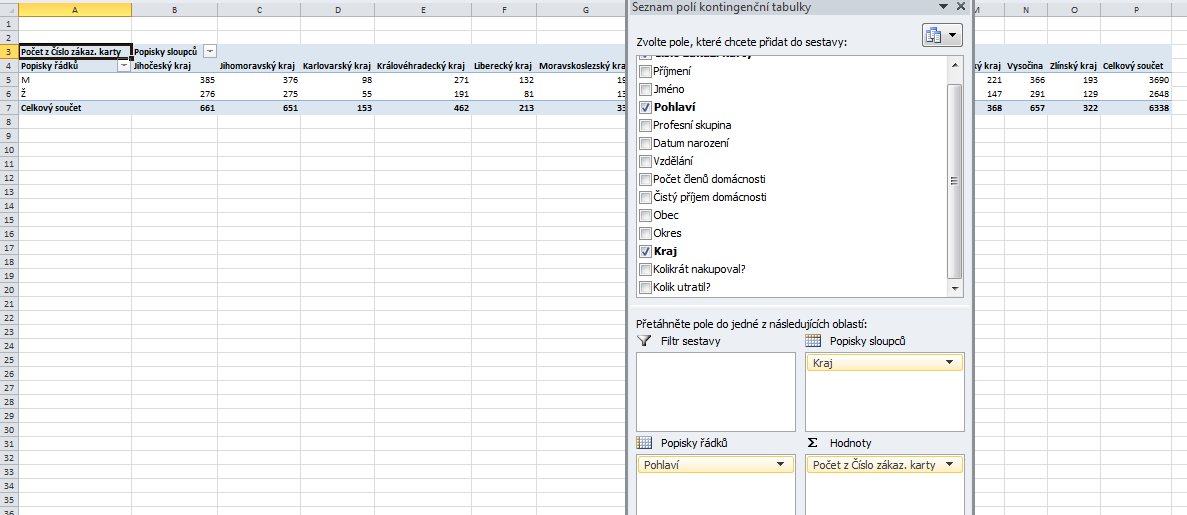
Je čistě na vás, jak kritéria rozmístíte do popisků řádků a do popisků sloupců – tabulka bude generovat stále stejné souhrny, maximálně se bude lišit přehledností, a i to je čistě subjektivní pojem. Svou roli může rovněž hrát to, jestli si chcete kontingenční tabulku prohlížet na obrazovce nebo ji potřebujete vytisknout. Osobně doporučuji následující:
- Sledujete-li hodnoty podle jednoho kritéria, umístěte toto kritérium do popisků řádků.
- Sledujete-li hodnoty podle dvou kritérií, umístěte jedno kritérium do popisků řádků a druhé do popisků sloupců. Do popisků řádků přitom dejte to kritérium, které může nabývat více hodnot: rozhoduji-li se například podle krajů a pohlaví, tak do popisků řádků raději umístím položku Kraj, která může nabývat 14 hodnot a položku Pohlaví, která nabývá pouze dvou hodnot, umístím do do popisků sloupců.
Co když ale potřebuji sledovat své zákazníky podle více kritérií, například i podle vzdělání? Následující obrázek zobrazuje dvě možnosti – první umístí položku Vzdělání do popisků řádků pod položku Kraj, druhá ji umístí do popisků sloupců pod položku Pohlaví:
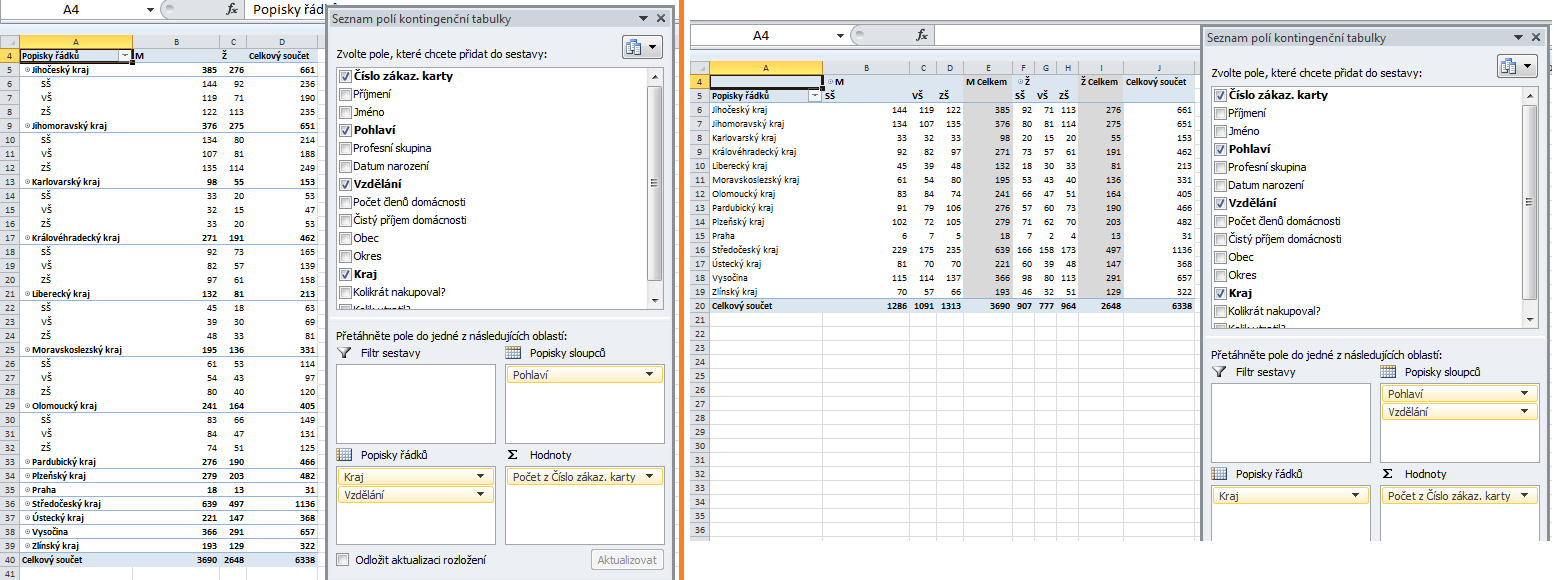
Zde se jeví jako přehlednější druhá varianta, tabulka se bude i celkem dobře tisknout. Přehlednost tabulky je dána tím, že možných hodnot vzdělání je (podobně jako u pohlaví) celkem málo, a takové štěstí bohužel vždy mít nemusíme. Pak bude lepší třetí kritérium umístit do filtru sestavy:
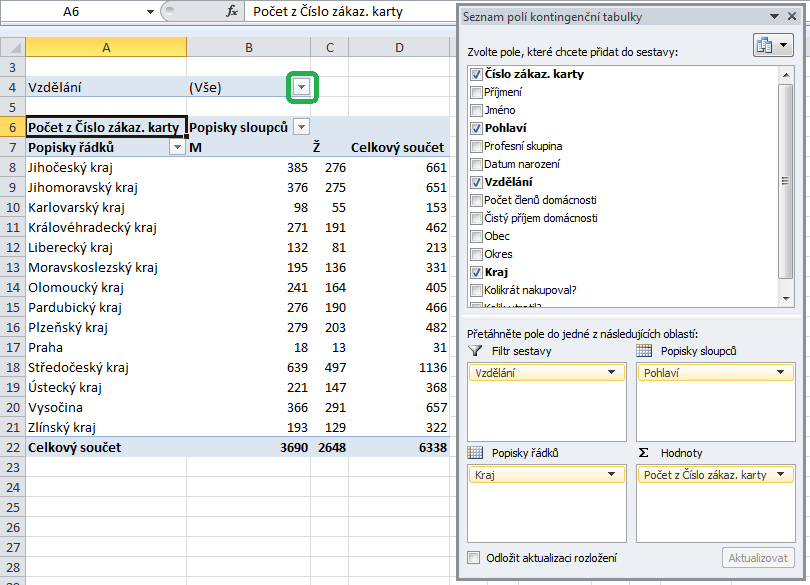
Na první pohled se nic nezměnilo, kromě toho, že nad kontingenční tabulkou přibyla podbarvená oblast Vzdělání. Pomocí šipky po její pravé straně ale můžeme vybrat z rozbalovacího seznamu tu konkrétní vzdělanostní skupinu, která nás zajímá, a tu zkoumat detailněji – například zde jsem si vyfiltroval jen vysokoškoláky:
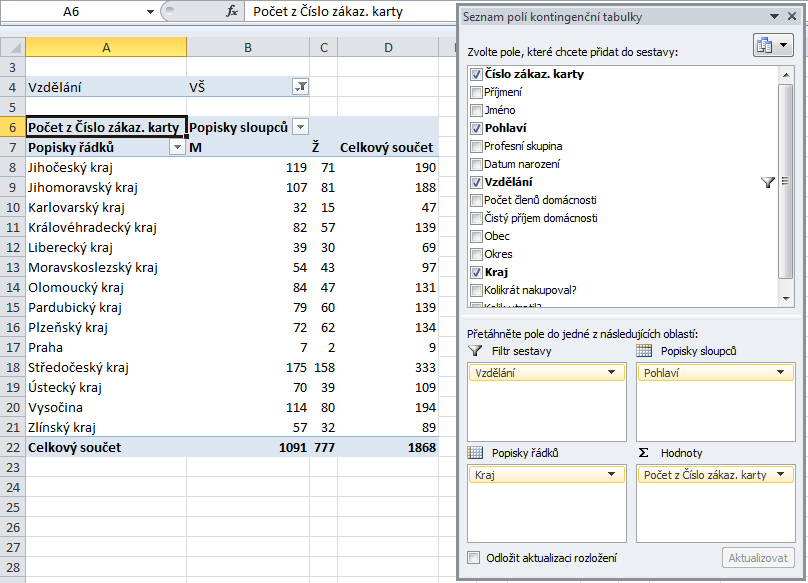
Tím kontingenční tabulka získala „třetí rozměr“, kdy sice na první pohled nevidím všechny údaje, ale vhodným filtrováním mohu zobrazit ty detaily, které mě právě zajímají. Kdybych měl filtr sestavy z tohoto příkladu vysvětlit ještě jinak, přirovnal bych ho k průhledným fóliím: na všech bude dvourozměrná tabulka s počty zákazníků podle krajů a podle pohlaví – na první fólii ale budou jen zákazníci se základním vzděláním, na druhé jen ti se středoškolským vzděláním a na třetí fólii jen vysokoškoláci. Poskládám-li tyto tři fólie na sebe, dostanu všechny zákazníky bez ohledu na vzdělání.
Zkusme si nyní všechno to, co jsme dosud s tabulkou našich zákazníků dělali, shrnout schematicky pomocí obrázků.
V první části našeho povídání jsme začali tím, že jsme chtěli zjistit, kolik máme v našem řetězci zákazníků. Přetáhli jsme tedy číslo zákaznické karty do pole hodnot a zjistili jejich celkový počet:

Pak jsme si ty zákazníky rozdělili podle krajů – toto kritérium jsme umístili do popisků řádků:
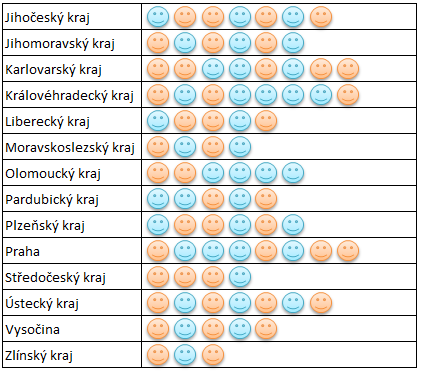
Dnes jsme chtěli sledovat počty zákazníků i podle pohlaví – toto kritérium jsme umístili do popisků sloupců:
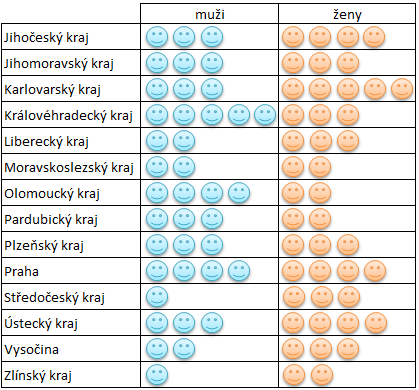
Na závěr jsme si do filtru sestavy přidali položku vzdělání, která nám umožňuje zobrazovat hodnoty v tabulce podle vzdělání zákazníka:
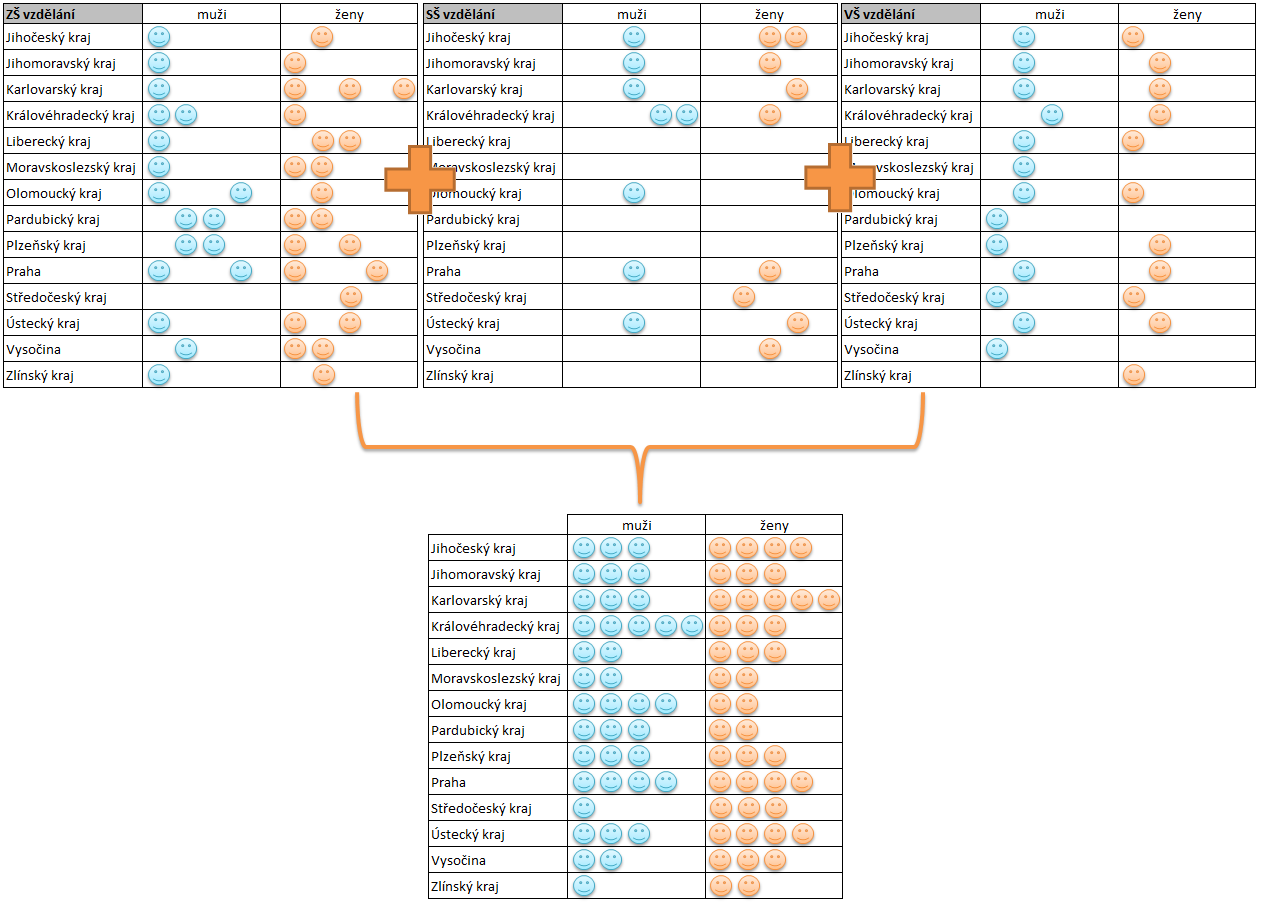
Tolik tedy malá smajlíková rekapitulace, doplním ještě pár poznámek k filtrům. Filtrovat se dají nejen hodnoty ve filtru sestavy, ale také hodnoty v popiscích řádků a popiscích sloupců – šipky rozbalovacích seznamů jsou i u nich, takže si je klidně vyzkoušejte. Filtrování záznamů v řádcích, sloupcích a sestavách má smysl zejména u rozsáhlejších tabulek – zobrazíte si díky nim jen ty hodnoty, které momentálně potřebujete.
I do filtrů sestavy můžete umísťovat více položek, chcete-li sledovat hodnoty podle ještě většího počt kritérií – na následujícím obrázku jsem přidal do filtru sestavy ještě položku Profesní skupina a vyfiltroval si jen muže důchodce:
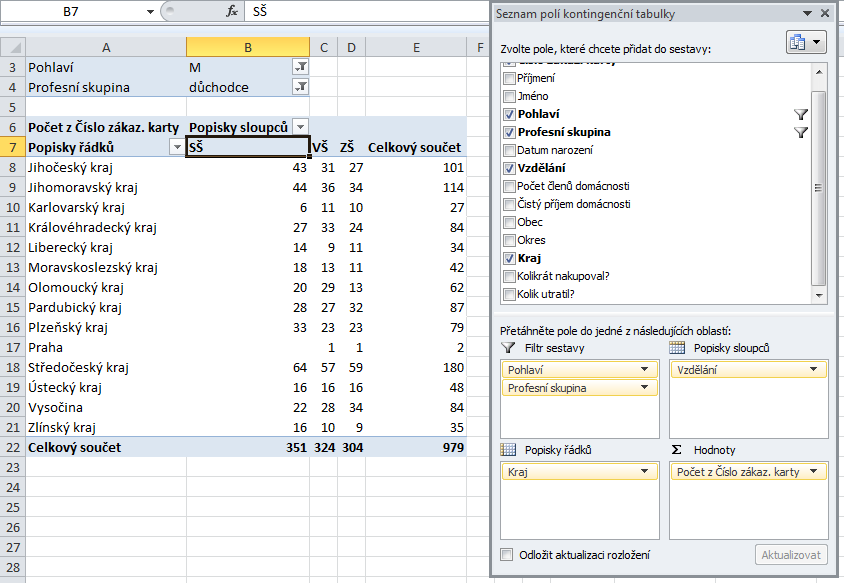
Podobně jako u popisků řádků a sloupců neexistuje ani u filtrů sestavy jednoznačné pravidlo, co kam umístit – podstatné je, aby tabulka byla přehledná pro vás a případně pro ty, kdož ji budou dále číst. Není často nutné dávat všechno do jedné kontingenční tabulky: nezapomínejte, že z jednoho zdroje dat můžete vytvořit více kontingenčních tabulek a každá může zobrazovat informace v tom uspořádání, v jakém obvykle budete potřebovat.
Kontingenční tabulka – úprava souhrnů, vzorce
Ukážeme si, jak můžeme v tabulce zobrazovat i jiné souhrny než počty.
Vycházet přitom budeme z ukázkových příkladů se zákazníky našeho hypermarketu, pro které bychom chtěli rozšířit nabídku sortimentu o luxusní zboží, například šperky. Jeho prodej bychom pilotně zavedli v kraji, v němž jsou zákazníci nejbohatší.
Který kraj to ale je? Připomeňme si, že ve zdrojové databázi máme u každého zákazníka mj. uveden čistý měsíční příjem domácnosti:
Budeme chtít tedy zjistit, v jakém kraji je tento čistý příjem nejvyšší. Logika nám velí umístit do popisku řádků položku Kraj a do pole hodnot umístit položku Čistý příjem domácnosti. Výsledkem bude následující kontingenční tabulka:
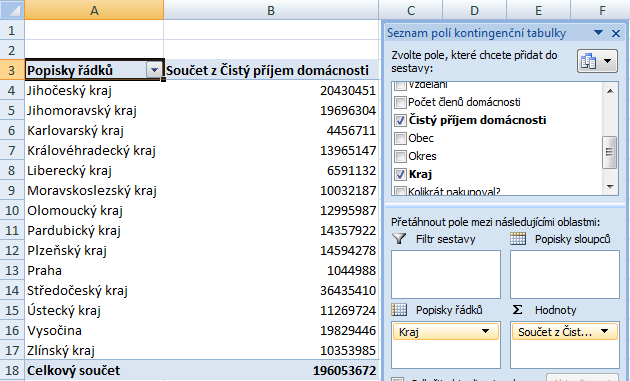
Ze zobrazených výsledků však moc moudří nebudeme: přetáhneme-li do pole hodnot číselnou položku, Excel její hodnoty v kontingenční tabulce automaticky sečte. Jinými slovy, získali jsme přehled, kolik v každém z krajů vydělávají všichni zákazníci dohromady. Tyto součty jsou zkresleny skutečností, že v každém kraji máme jiný počet zákazníků (již v prvním dílu jsme zjistili, že zatímco v Praze máme jen 31 zákazníků, ve Středočeském kraji jich je 1136). Abychom dospěli k relevantnímu závěru, musíme součet příjmů zákazníků vydělit jejich počtem – tj. vypočítat průměrný čistý příjem domácnosti.
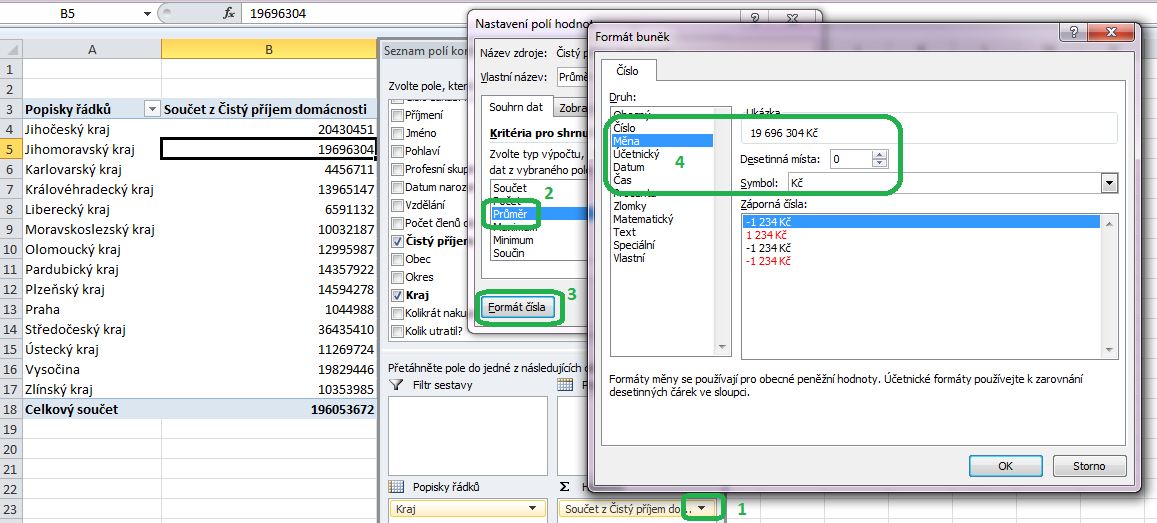
Toho dosáhneme celkem snadno – změníme způsob zobrazení čistého příjmu domácnosti v poli hodnot, kdy místo souhrnu Součet, který Excel implicitně aplikuje na číselné hodnoty, použijeme souhrn Průměr. Klepneme na šipku po pravé straně položky Součet z Čistý příjem domácnosti a z nabídky zvolíme příkaz Nastavení polí hodnot (viz obr.):
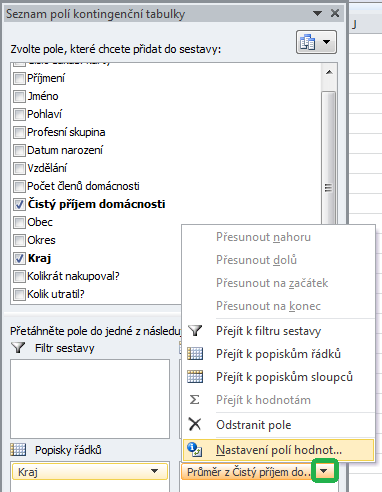
Jako kritérium pro shrnutí pole použijeme funkci Průměr a přes tlačítko Formát čísla naformátujeme hodnoty jako měnu (viz obr.):
Výsledkem by měla být kontingenční tabulka, z níž po seřazení hodnot s překvapením zjistíme, že nejbohatší rodiny jsou v Praze:
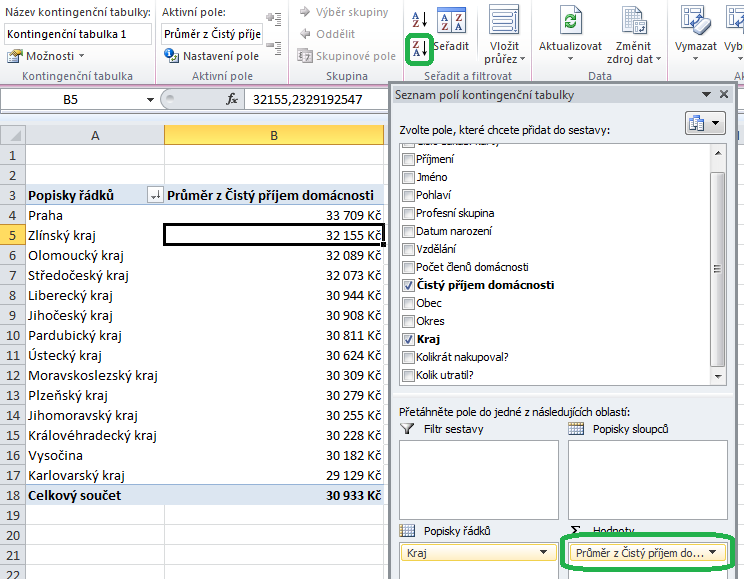
Ukázali jsme si tedy, jak lze ovlivňovat způsob výpočtu souhrnů v poli hodnot. Vyzkoušejte si to sami ještě na dvou dalších příkladech – jsou celkem jednoduché.
Příklad 1
Následující obrázek ukazuje, jak bychom například zjistili příjmy nejchudších a nejbohatších domácností v závislosti na počtu jejich členů – stačí příjem domácnosti umístit do pole hodnot dvakrát a u jedné položky jako funkci souhrnu vybrat minimum, u druhé pak maximum:
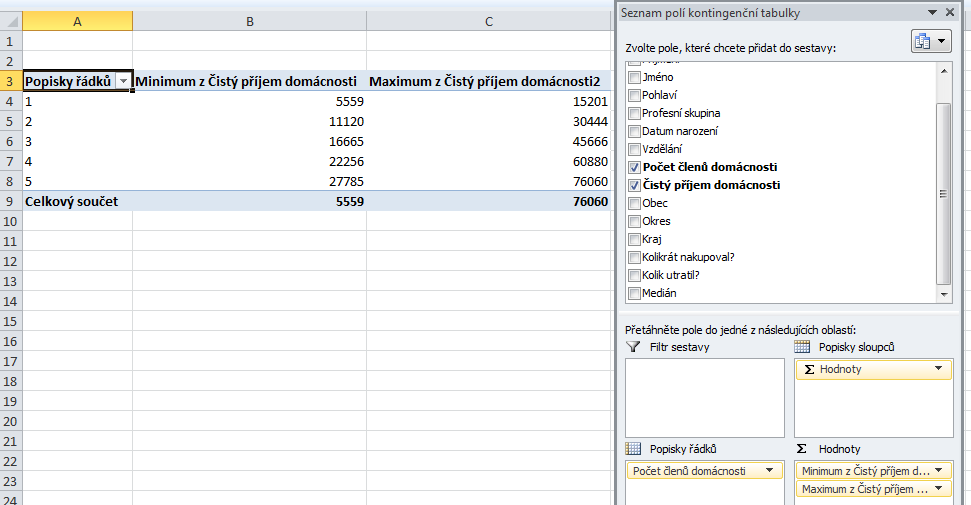
Příklad 2
Ve cvičení 1 jsme pracovali se seznamem okresů a měli zjistit počet obcí a počet obyvatel. Zdrojová tabulka (najdete ji v ukázkových příkladech na listu Okresy) vypadala následovně:
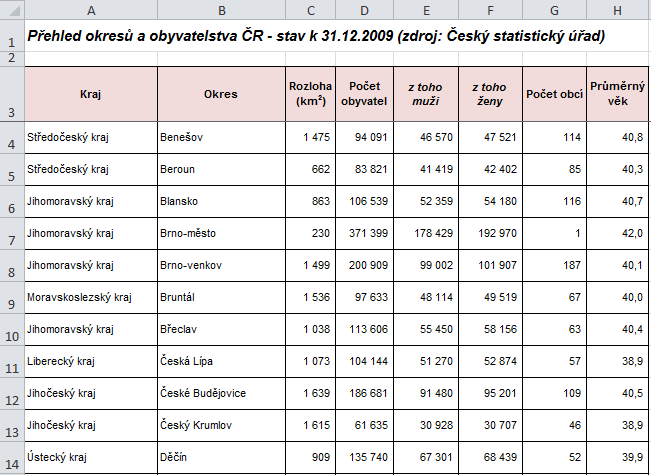
Následující kontingenční tabulka pak zobrazuje pro každý kraj počet obcí, okresů, obyvatel, celkovou rozlohu a průměrný věk obyvatel – opět stačí u jednotlivých položek v poli hodnot použít vhodnou souhrnnou funkci:
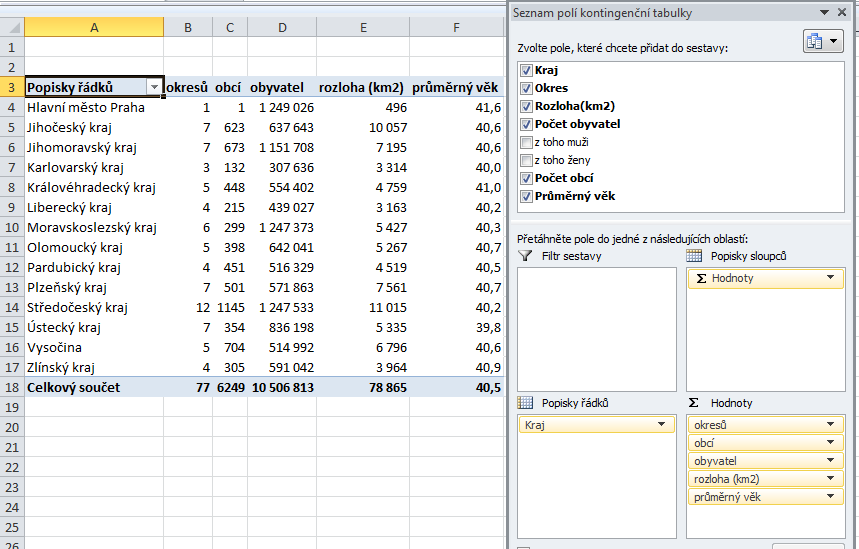
V kontingenční tabulce jsem po jejím vytvoření přejmenoval popisky sloupců v prvním řádku kontingenční tabulky, což se projevilo v názvech položek v poli hodnot. Pro pole Okresů je použit souhrn Počet, pro pole Obcí, Obyvatel a Rozloha je použit souhrn Součet, pro pole Průměrný věk souhrn Průměr. U počtu obyvatel a rozlohy jsem nastavil formát bez desetinných míst s oddělovačem tisíců, průměrný věk zobrazuji s přesností na jedno desetinné místo.
Cvičení
Pracujte se souborem kt.xls na adrese: K:\ProŽáky\Bečvářová Silvie\Podklady\EXCEL. Pro každé cvičení vyberte jinou záložku.
C1 – Okresy
Procvičte si vytváření jednoduchých kontingenčních tabulek sami na jiném příkladu – na listu Okresy najdete přehled jednotlivých okresů ČR s údaji o jejich rozloze, obyvatelstvu a počtu obcí v každém okrese. Tabulka vypadá zhruba následovně:
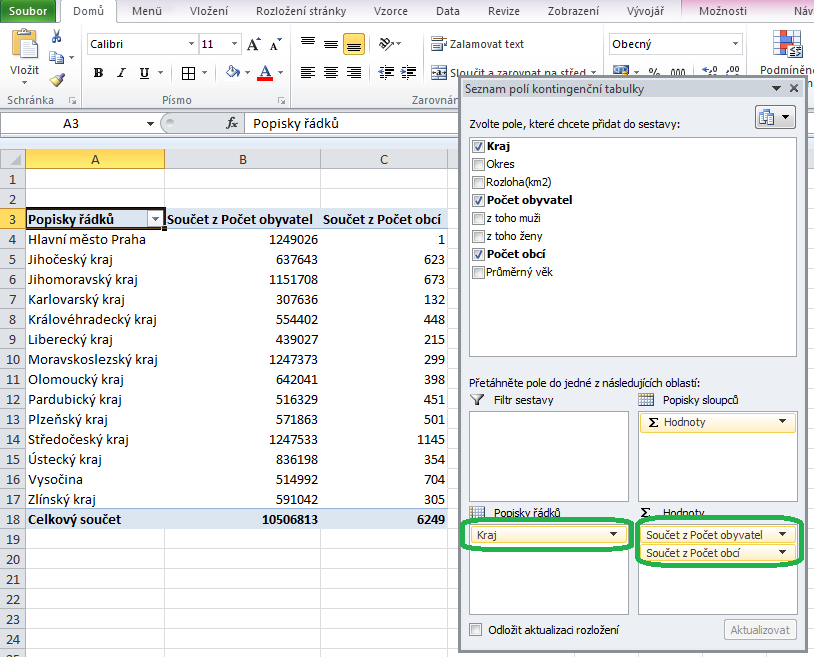
Vaším úkolem je vytvořit přehled, který zobrazí počet obyvatel a počet obcí v jednotlivých krajích. Vytvořte tedy z tabulky okresů (což budou v naší terminologii zdrojová data) novou kontingenční tabulku a vhodným přetažením vhodných položek na vhodná místa z ní udělejte požadovaný přehled. Pokud se vám nebude dařit, poradí obrázek na konci tohoto příspěvku. Malá rada – nikde není řečeno, že v každé části kontingenční tabulky může být jen jedna položka.
Řešení zachycuje následující obrázek. Všimněte si, že pokud do pole hodnot přetáhneme číselné položky jako byly počty obyvatel nebo počty obcí, Excel je pro kontingenční tabulku sečte (což shodou okolností chceme), zatímco při přetahování nečíselných položek implicitně zobrazuje jejich počet.
C2 – Callcentrum
Firma vyrábějící kosmetiku provozuje telefonickou informační linku, na níž operátoři zodpovídají dotazy zákazníků. Úkolem operátorů je nejen vyřídit zákazníkův požadavek, ale také mu nabídnout a prodat nějaký další výrobek či službu. Po skončení hovoru operátor zaznamená do informačního systému, o čem se zákazníkem hovořil, a je následně připraven přijmout další hovor. Aktivity operátorů eviduje provozní systém, jenž důležité věci zaznamenává do následující tabulky:
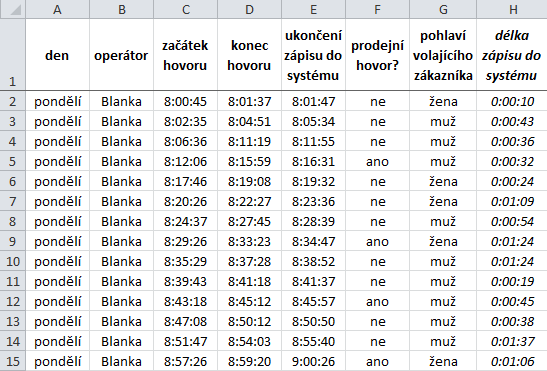
Tuto tabulku najdete v ukázkovém souboru na listu Callcentrum. Vaším úkolem bude pomocí kontingenčních tabulek zjistit odpovědi na následující otázky:
- V který den týdne volalo nejvíce zákazníků a v který den nejméně?
- Který operátor vyřídil za týden nejméně hovorů?
- Který den týdne bylo nejvíc prodejních hovorů a který den nejméně?
- Převládají celkově mezi volajícími zákazníky muži nebo ženy?
- Který operátor v týdnu prodal nejvíc výrobků mužům a který ženám?
C3 – Zákazníci
Na listu Zákazníci zjistěte příjmy nejchudších a nejbohatších domácností v závislosti na počtu jejich členů.
Stačí příjem domácnosti umístit do pole hodnot dvakrát a u jedné položky jako funkci souhrnu vybrat minimum, u druhé pak maximum.
C4 – Okresy
Na listu Okresy zjistěte pro každý kraj počet obcí, okresů, obyvatel, celkovou rozlohu a průměrný věk obyvatel.
Stačí u jednotlivých položek v poli hodnot použít vhodnou souhrnnou funkci.
C5 – Analýza prodeje ve školním bufetu
Na adrese K:\ProŽáky\Bečvářová Silvie\Podklady\EXCEL si stáhněte tabulku KT-bufet.
Jedná se o tabulku s daty o prodeji v školním bufetu za měsíc březen.
Pomocí kontingenční tabulky analyzujte prodeje podle jednotlivých kategorií a dní v týdnu.
Úkoly:
- Vytvořte nový sloupec „Celkový výnos“, který bude spočítán jako
Cena za kus * Počet prodaných kusů. - Vytvořte kontingenční tabulku, která:
- zobrazí celkový výnos podle kategorií.
- Seřaďte výsledky podle velikosti výnosu.
Zdroje: