Databáze obecně je prostor či nástroj k uchování a organizaci nějakých dat. Databází je mnoho druhů, my se v tomto článku budeme zaobírat pouze jedním a pravděpodobně nejpoužívanějším typem – databázemi relačními. Relační databáze uchovávají data v tabulkách a umožňují nám s nimi pohodlně manipulovat, většinou pomocí speciálního jazyka SQL.
Jazyk SQL (Structured Query Language – strukturovaný dotazovací jazyk) je jakási „strojová“ angličtina uzpůsobená pro manipulaci s daty. V praxi to funguje tak, že pošleme databázi příkaz v SQL a databáze nám vrátí jako výsledek požadovaná data.
Software kolem toho
Existuje několik různých databázových serverů. Jsou to programy či služby, které schraňují několik databází a umožňují manipulaci s jejich daty. Nejpoužívanější jsou databázové servery MySql, MS SQL, PostgreSQL, Oracle, Firebird. Všechny umí jazyk SQL, základ je stejný, ale v některých (mnohdy podstatných) detailech se tyto databáze a i jejich verze jazyka SQL liší. Já se budu držet databázového serveru Microsoft SQL Server 2005, který je v Express edici dostupný zdarma. Ukázky tedy nemusí fungovat jinde, datové typy se mohou také jmenovat jinak. Principy jsou však většinou stejné.
Uspořádání dat v databázi
V relačních databázích jsou data uchovávána v tabulkách (tzv. relacích). V jedné databázi může být více tabulek, každá se používá pro specifický druh dat. Tabulka má (zcela přirozeně) sloupce a řádky – každý řádek je jeden záznam a v každém sloupci je hodnota předem definovaného typu. Lepší je to ukázat na příkladu (v tomto i v ostatních příkladech jsou jména fiktivní, podobnost s existujícími osobami je čistě náhodná):
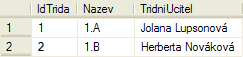
Jedná se o tabulku tříd ve škole, se kterou budeme pracovat i dále. Tato tabulka má 3 sloupce – IdTrida, Nazev a TridniUcitel. To jsou data, která si chceme pamatovat o každé třídě. Každý řádek je pak jedna konkrétní třída a obsahuje k ní příslušné informace.
Datové typy, primární klíče a podobná zvířátka
Každá tabulka by měla mít tzv. primární klíč – je to speciální sloupec, který slouží k jednoznačné identifikaci záznamu v tabulce. Žádné dva řádky nesmí mít v tomto sloupci stejnou hodnotu, každý řádek musí mít hodnotu primárního klíče jedinečnou (unikátní) v rámci tabulky. Většinou se to řeší tak, že tento sloupec nastavíme jako identity field (někdy také auto_increment). Do tohoto sloupce se díky tomu samy dosazují čísla postupně od zadané počáteční hodnoty. Pokud tedy do prázdné tabulky přidáme jeden záznam, dostane třeba číslo 1, pokud přidáme druhý, dostane číslo 2 atd. Za chvíli máme v tabulce 10 záznamů a rozhodneme se jeden smazat, třeba záznam číslo 5. Pokud přidáme další záznam, dostane ale číslo 11. Nejde totiž o to, aby bylo číslování souvislé (aby nebyly díry), ale aby každý sloupec měl hodnotu primárního klíče jinou. V naší ukázkové tabulce byl primární klíč sloupec IdTrida.
Každý sloupec musí mít svůj datový typ, který přesně určuje typ dat, které v daném sloupci budou. Nejběžnější datové typy jsou varchar (textová hodnota), int (číselná hodnota), bit (hodnota Boolean) a datetime (datum a čas). Datový typ varchar musí ještě uvádět maximální délku textu, kterou je schopen pojmout, pokud je to na opravdu dlouhé texty (celé články), místo maximální délky se uvádí slovo max. Vše uvidíte na ukázce vytvoření tabulky.
Ve všech databázích existuje ještě speciální hodnota NULL, která znamená něco ve smyslu nevyplněno. Můžeme ji pro konkrétní sloupce v tabulce povolit, čímž řekneme, že údaj nemusí být vyplněn.
Datové typy
V SQL Server mají všechny sloupce, proměnné nebo výrazy své definované datové typy. Ty určují, jakého typu jsou hodnoty, které daný sloupec nebo jiný logický objekt může obsahovat. Po každé když se snažíte založit sql tabulku, proměnnou nebo výraz, je striktně požadována definice, která určuje sql datové typy.
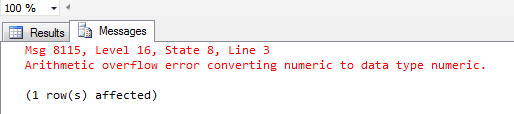
Nesprávným zvolením datového typu u objektů se můžete později dostat do velkých problémů. Typickým příkladem je volba datového typu pro peněžité vyjádření např. tržeb, kdy volíme příliš krátký číselný formát protože jednoduše předpokládáme, že firma nebude mít nikdy vyšší tržby než XYZ. Za pár let se ale budeme divit až dostaneme tento Error – Aritmetic overflow error converting numeric to data type numeric
Kromě vlastních datových typů v t-sql, které si můžete v SQL Server definovat pomocí .NET frameworku, systém nabízí systémové datové typy. Těm se bude věnovat tento přehled.
SQL Datové typy – Kategorie
System data types jsou v rámci SQL Server rozděleny do 7 logických kategorií:
Přesná čísla (Exact Numerics)
- BIGINT
- BIT
- DECIMAL
- INT
- MONEY
- NUMERIC
- SMALLINT
- SMALLMONEY
- TINYINT
Přibližná čísla (Approximate Numerics)
- FLOAT
- REAL
Podrobněji článek o číselných datových typech v SQL
Datum a čas (Date and Time)
- DATE
- DATETIME
- DATETIME2
- DATETIMEOFFSET
- SMALLDATETIME
- TIME
Podrobněji článek datumových datových typech
Textové řetězce vč. UNICODE (Character strings + UNICODE)
- CHAR + NCHAR
- VARCHAR + NVARCHAR
- TEXT + NTEXT
Binární textové řetězce (Binary strings)
- BINARY
- VARBINARY
- IMAGE
Ostatní datové typy
- CURSOR
- TIMESTAMP
- HIERARCHYID
- UNIQUEIDENTIFIER
- SQL_VARIANT
- XML
- TABLE
Více informací:
Vytvoření tabulky CREATE
Do skriptu vložte tento příkaz, který vytvoří naši tabulku tříd (tabulka se jmenuje Tridy).
CREATE TABLE [Tridy] ( [IdTrida] INT NOT NULL PRIMARY KEY IDENTITY(1,1), [Nazev] VARCHAR(50) NOT NULL, [TridniUcitel] VARCHAR(100) NOT NULL )
- Příkaz CREATE TABLE slouží k vytvoření tabulky. Za ním musí následovat název tabulky a pak v závorce seznam sloupců s jejich datovými typy a nastavením, jednotlivé sloupce se oddělují čárkou, pro přehlednost dávám každý na nový řádek).
- Druhý řádek definuje primární klíč tabulky – první je vždy název sloupce, pak následuje datový typ a pak další nastavení. [IdTrida] je tedy název sloupce, INT je datový typ číslo, NOT NULL znamená, že nepovolujeme hodnotu NULL, tím pádem musí být položka vždy vyplněna, PRIMARY KEY říká, že se jedná o primární klíč (často se primární klíče deklarují zvlášť jako tzv. constraint – omezení, ale nám zatím stačí toto). IDENTITY(1,1) znamená, že se budou do tohoto sloupce dosazovat automaticky číselné hodnoty – první číslo je počáční hodnota pro první záznam a druhé číslo je přírůstek (každý další přidaný záznam má přiřazenou hodnotu vyšší než naposledy přidaný záznam právě o tento přírustek). Tím tedy máme nadefinovaný primární klíč.
- Třetí řádek definuje druhý sloupec tabulky – název třídy. [Nazev] je název sloupce, VARCHAR(50) je datový typ pro textovou hodnotu, číslo v závorce je již zmiňovaná maximální délka textu a NOT NULL již známe, název tedy musí být vyplněn. Čtvrtý řádek je téměř stejný, bude obsahovat jméno a příjmení třídního učitele, maximální délka je 100 znaků.
Je dobré zvyknout si uzavírat názvy sloupců a tabulek do hranatých závorek, jazyk SQL obsahuje mnoho klíčových slov a pokud bychom chtěli pojmenovat sloupec klíčovým slovem, bez hranatých závorek by to nešlo. Proto je lepší je dávat všude, přestože to není nutné. Je dobré také upozornit na to, že každá firma má svůj vlastní styl co se týče pojmenování tabulek a sloupců (někde se pojmenovávají česky, jinde anglicky, primární klíče někde začínají předponou Id, jinde Id_, jinde tak končí, někde se píší klíčová slova velkými písmeny, někde malými atd.) Je jedno, jaký styl člověk používá, ale rozhodně je více než vhodné použít v celé databázi styl stejný. Pokud nejste ve firmě a nenutí vás nikdo do konkrétního stylu, vymyslete si svůj a důsledně jej dodržujte.
Vazby mezi tabulkami
V drtivé většině případů chceme uchovávat data, která spolu nějak souvisí. Protože chceme do databáze přidat ještě tabulku žáků, musíme si tedy něco říci o tom, jak reprezentovat vazby mezi záznamy. Mohl bych vyrobit krásnou tabulku žáků (údaje jsou opět fiktivní), která ovšem bude mít hned několik nedostatků.
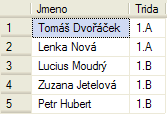
Jako první bych viděl to, že jména a příjmení jsou v jednom sloupci. Pokud bych chtěl setřídit žáky podle příjmení, abych v nich mohl snadno někoho vyhledat, bylo by to složité a pomalé (třídit lze jednoduše podle sloupců, ale jinak to až tak triviální není).
Lepší tedy jistě bude udělat dva sloupce Jmeno a Prijmeni, pokud potřebujeme vypsat někde celé jméno, poskládáme si to až v aplikaci samotné a ne na úrovni databáze. Druhým nedostatkem je sloupec druhý – u každého žáka je vypsán název třídy. Pokud je žáků 5, ještě to tak nevadí, pokud jich bude 500 a nějaká třída se nám přejmenuje, budeme muset změnit mnoho záznamů v tabulce (dokonce ve dvou – v tabulce tříd i v tabulce žáků). Lepší by bylo vytvořit něco jako odkaz na záznam v tabulce tříd, pro přejmenování třídy stačí pak jen změnit název v tabulce tříd.
A v neposlední řadě tato tabulka žáků nemá primární klíč (to, co vidíte nalevo jsou jen čísla řádků, ale to je věc programu, který s databází pracuje, v samotné tabulce takový údaj není). Pokud tedy budeme chtít smazat nějakého žáka, nemáme jej jak identifikovat – dva lidé jmenující se stejně je poměrně běžná věc.
Primární klíč zvládneme přidat, vytvořit dva sloupce místo jediného také. Problémem je tedy zatím ta vazba. Kvůli ní se částečně také dělá primární klíč. Místo názvu třídy do tabulky žáků uložíme hodnotu primárního klíče konkrétní třídy z tabulky tříd. Kromě toho, že se hodnoty primárního klíče pro záznam většinou nemění (sice mohou, ale obyčejně se to nedělá), je porovnávání čísel rychlejší než porovnávání textů, což oceníme v okamžiku, kdy potřebujeme vypsat k jednotlivým žákům jejich třídní učitele.
Několik jednoduchých zásad pro návrh tabulek
- Údaje stejného druhu patří do jedné tabulky. Nebudeme tedy pro každou třídu vytvářet novou tabulku pro její žáky, ale všechny žáky dáme do jedné tabulky a přidáme do ní speciální sloupec pro identifikaci třídy. Manipulace s daty v jedné velké tabulce je lepší než manipulace s deseti tabulkami.
- Neopisujeme data z jiných tabulek pro vyjádření vztahu. Místo vypisování názvu třídy u každého žáka uvedeme hodnotu primárního klíče tabulky, čímž odkážeme na konkrétní záznam. Pokud bychom neměli pro třídy tabulku, je vhodné ji vytvořit, pokud víme, že se hodnoty budou často opakovat.
- Každá tabulka má mít primární klíč. Abychom mohli jednoznačně identifikovat záznamy v tabulce, důsledně dodržujte vytváření primárních klíčů opravdu do každé tabulky.
Jistě by se dalo najít více zásad, ale tyto tři myslím stačí. Databáze jsou optimalizované pro databáze, které dodržují tato pravidla. Pokud tedy vazby vytvoříte tak, jak se mají, dosáhnete vyššího výkonu. Správně navržená tabulka žáků může vypadat takto:
CREATE TABLE [Zaci] ( [IdZak] INT NOT NULL PRIMARY KEY IDENTITY(1,1), [Jmeno] VARCHAR(50) NOT NULL, [Prijmeni] VARCHAR(50) NOT NULL, [Pohlavi] BIT NOT NULL, [Narozen] DATETIME NOT NULL, [IdTrida] INT NOT NULL REFERENCES [Tridy]([IdTrida]), [Telefon] VARCHAR(20) )
- Většinu toho již známe, [IdZak] je primární klíč s automatickým dosazováním hodnot, [Jmeno] a [Prijmeni] je jasné, sloupec [Pohlavi] je typu BIT (přípustné hodnoty 0 – ženanebo 1 – muž), [Narozen] je typu DATETIME, což je datum a čas, [Telefon] je text a nemá NOT NULL, takže jej nemusíme vždy vyplnit (ne všichni prvňáčci mají mobil).
- Záměrně jsem ale přeskočil řádek [IdTrida], datový typ číslo a musí být vždy vyplněno. Klíčové slovo REFERENCES deklaruje vazbu mezi tabulkami (tzv. foreign key – cizí klíč). Za ním následuje název tabulky, do které odkazujeme a v závorce název sloupce (v našem případě primární klíč). To je celá věda, můžeme za tuto deklaraci přidat ještě ON DELETE CASCADE či ON DELETE SET NULL. Tím definujeme, co se má stát, pokud smažeme záznam, na který se odkazuje – první možnost smaže i tento záznam (pokud bychom tedy smazali třídu, smažou se automaticky i všechny záznamy, které na ni odkazují), druhá možnost nastaví hodnotu v tomto sloupci na NULL (všem žákům právě smazané třídy by se sloupec IdTrida nastavil na hodnotu NULL). To zatím používat nebudeme.
Vkládání dat do tabulek INSERT
Pokud chceme do tabulky přidat záznam, používáme příkaz INSERT. Musíme vždy vyplnit všechny sloupce označené NOT NULL, nevyplňujeme primární klíč, pokud má nastavenou IDENTITY, protože se vyplní sama. Struktura příkazu INSERT vypadá takto:
INSERT INTO [Tridy] ([Nazev], [TridniUcitel]) VALUES ('1.A', 'Jolana Lupsonová')
INSERT INTO [Tridy] ([Nazev], [TridniUcitel]) VALUES ('1.B', 'Herberta Nováková')
INSERT INTO říká, že se má přidat záznam, následuje název tabulky, do které záznam přidáváme. Do závorky za sebe uvedeme názvy sloupců, které chceme vyplnit, oddělené čárkou. Pak následuje mimo závorku klíčové slovo VALUES a za ním v závorce hodnoty, které se do sloupců dosadí (v tom pořadí, v jakém jsme vypsali sloupce). Textové hodnoty ohraničujeme znaky ‚ (apostrof), čísla píšeme bez apostrofů.
- Pokud spustíte tyto dva příkazy, vloží se do tabulky tříd tyto dvě třídy – třída 1.A s třídní učitelkou Jolanou Lupsonovou a třída 1.B s paní učitelkou Herbertou Novákovou (jména jsou opět fiktivní). První záznam se očísloval číslem 1 a druhý číslem 2, pokud jsme před tím do tabulky již nezasahovali. Tady můžeme jména a příjmení třídního učitele dát dohromady, nemáme totiž žádnou tabulku učitelů (pro účely tohoto článku je to zbytečné), pakliže bychom ji měli, dali bychom sem jen odkaz na cizí klíč v tabulce učitelů.
Vložte tedy ještě tyto žáčky do tabulky žáků:
INSERT INTO [Zaci] ([Jmeno], [Prijmeni], [Pohlavi], [Narozen], [IdTrida], [Telefon])
VALUES ('Tomáš', 'Dvořáček', 1, 'January 3, 2001', 1, NULL)
INSERT INTO [Zaci] ([Jmeno], [Prijmeni], [Pohlavi], [Narozen], [IdTrida], [Telefon])
VALUES ('Lenka', 'Nová', 0, 'November 6, 2000', 1, '314 212 111')
INSERT INTO [Zaci] ([Jmeno], [Prijmeni], [Pohlavi], [Narozen], [IdTrida], [Telefon])
VALUES ('Lucius', 'Moudrý', 1, 'August 24, 2001', 2, '987 654 321')
INSERT INTO [Zaci] ([Jmeno], [Prijmeni], [Pohlavi], [Narozen], [IdTrida], [Telefon])
VALUES ('Zuzana', 'Jetelová', 0, 'June 19, 2001', 2, NULL)
INSERT INTO [Zaci] ([Jmeno], [Prijmeni], [Pohlavi], [Narozen], [IdTrida], [Telefon])
VALUES ('Petr', 'Hubert', 1, 'March 23, 2000', 2, NULL)
Pokud chceme předat datum, máme několik povolených formátů pro jeho předání. U každé databáze je to trochu jinak, pokud předáváme jen datum, můžeme jej zadat ve formátu Měsíc Den, Rok, kde měsíc je anglický název měsíce. Pokud zadáváme datum i čas zároveň, doporučuje se tento formát 2007-08-23 15:36:24.000. Pokud nechceme zadat nějaký údaj, napíšeme místo něj NULL (ne do apostrofů).
Více:
Výpis záznamů z tabulky SELECT
Úkol: Představte si tabulku obsahující data o lidech. Úkolem bude vybrat z tabulky “Lide” všechny, kteří jsou narozeni mezi rokem 1.1.1995 a 31.12.2005 včetně. Ve výsledku skriptu nás zajímá jméno, příjmení a datum narození. Všechny záznamy by měly být seřazeny sestupně podle příjmení.
Příkaz SELECT jako první v pořadí
Touto klauzulí databází říkáme, že chceme zobrazit nějaká data. Současně v ní definujeme jaká data (Sloupce) chceme vybrat.
Průběžný SQL skript:
SELECT Jmeno, Prijmeni, Datum_Narozeni
Pokud bychom tento skript pustili nad databází, tak by výsledkem byla chyba. Důvodem je to, že jsme nedeklarovali odkud mají být pole “Jmeno”, “Prijmeni” a “Datum_Narozeni” vybrany. Je tedy potřeba vybrat tabulku.
Příkaz FROM
Klauzulí definujeme, kde se informace z předchozího kroku nacházejí = v jaké tabulce je najdeme. Hledam budeme v tabulce “Lide”
Průběžný SQL skript:
SELECT Jmeno, Prijmeni, Datum_Narozeni FROM Lide
Tento skript již bude funkční a vrátí nám všechny záznamy z tabulky Lide, kde vybranymi sloupci bude Jmeno, Prijmeni a Datum_Narozeni
Příkaz WHERE
Přichází čas na to, abychom výsledek předchozího kroku omezili na Datum narozeni. Obecně tato klauzule slouží k nadefinování omezujících podmínek.
Průběžný SQL skript:
SELECT Jmeno, Prijmeni, Datum_Narozeni FROM Lide WHERE Datum_Narozeni >= '1995-01-01' AND Datum_Narozeni <= '2005-12-31'
Podmínka obsahuje sloupec, který chceme nějak omezit. Vidíme, že v
SQL můžeme používat operátory jako v matematice ><= atd. Podmínka
by se data zjednodušit použitím operátoru “BETWEEN“. V tomto případě by podmínka vypadala WHERE Datum_Narozeni BETWEEN '1995-01-01' AND '2005-12-31'.
Příkaz ORDER BY
Poslední část úkolu je výsledek uspořádat. To se dělá přes příkaz ORDER BY kdy za klauzuli ještě můžeme napsat (není to povinné), jak chceme data uspořádat (ASC – vzestupně nebo DESC – sestupně). Pokud způsob řazení nevyplníme, řadí se data vzestupně (ASC)
Výsledný SQL skript:
SELECT Jmeno, Prijmeni, Datum_Narozeni FROM Lide WHERE Datum_Narozeni >= '1995-01-01' AND Datum_Narozeni <= '2005-12-31' ORDER BY Datum_Narozeni DESC
SELECT [Zaci].[Prijmeni], [Tridy].[Nazev] FROM [Zaci] JOIN [Tridy] ON [Tridy].[IdTrida] = [Zaci].[IdTrida] ORDER BY [Tridy].[Nazev], [Zaci].[Prijmeni]
Operátory
| Operátor | Popis | Příklad |
| = | Rovnost | |
| <> | Nerovnost, Poznámka: v některých verzích SQL se píše != | |
| > | Větší než | |
| < | Menší než | |
| >= | Větší než nebo rovno | |
| <= | Menší než nebo rovno | |
| BETWEEN | Mezi hodnotami | WHERE název_sloupce BETWEEN hodnota1 AND hodnota2 |
| LIKE | Podobné určitému vzoru (% libovolný počet libovolných znaků; _ jeden libovolný znak; [znaky] jeden ze znaků; [ˆznaky] nebo [!znaky] není to jeden ze znaků) | WHERE jnázev_sloupce LIKE vzor; |
| IN | Více hodnot ve sloupci | WHERE název_sloupce IN (hodnota1, hodnota2, …) |
Logické spojky operátorů
| AND | Spojení dvou podmínek, musí platit obě zároveň |
| OR | Spojení dvou podmínek, platí jedna, druhá nebo obě |
Shrnutí
Na těchto příkladech jsme si ukázali mnoho variant příkazu SELECT a různé specifikace kritérií. Známe tedy klíčové slovo ORDER BY, kterým dovedem třídit záznamy podle definovaných sloupců, klíčové slovo DESC, které řadí sestupně (ORDER BY [Prijmeni] řadí od A do Z, ORDER BY [Prijmeni] DESC řadí od Z do A). Umíme také specifikovat podmínky pomocí slova WHERE, operátory jsou přesně jako v jazyce Visual Basic – (je menší <, je větší >, je menší nebo rovno <=, je větší nebo rovno >=, rovná se = a nerovná se <>), stejně jsou i logické operátory (AND – a, OR – nebo, NOT – ne).
Spojení dvou tabulek JOIN
Zvlášte u posledního příkladu na seřazení podle třídy a příjmení by se hodilo řadit ne podle ID třídy, ale podle názvu třídy, a místo ID vypsat právě název této třídy. Toho dosáhneme na úrovni databáze příkazem JOIN.
Je to již trochu složitější – protože tabulky mohou obsahovat sloupce stejných názvů, je dobré před každý název sloupce přidat ještě název tabulky, ze které pochází. Vybíráme tedy sloupec [Prijmeni] z tabulky [Zaci] a sloupec [Nazev] z tabulky [Tridy] z tabulky [Zaci] a k výsledkům připojíme tabulku [Tridy] tak, aby hodnoty sloupců [IdTrida] v obou tabulkách byly stejné. Setřídění už je jasné.
Pokud spojujeme dvě tabulky, je nutné vždy uvést podmínku spojení – podle jakého klíče se k sobě záznamy z tabulek mají přiřazovat. V našem případě spojíme, když se [Zaci].[IdTrida] rovná [Tridy].[IdTrida].
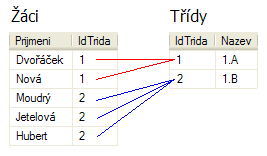
Zkrátka ke každému řádku v tabulce [Zaci] se najde záznam s odpovídajícím ID v tabulce [Tridy].
Ještě existuje rozdíl mezi tzv. INNER (vnitřní) a OUTER (vnější) joinem. Ani jeden se nás nyní netýká, protože ve sloupci IdTrida nesmí být hodnota NULL, ale je dobré rozdíl mezi nimi zmínit. Pokud má cizí klíč hodnotu NULL, INNER JOIN jej vynechá a s ničím jej nespojí, naopak OUTER JOIN spojení provede a do všech sloupců z připojované tabulky nastaví hodnotu NULL.
Samotný JOIN, který jsme použili nyní, je automaticky INNER JOIN. Pokud by se v tabulce [Zaci] ve sloupci [IdTrida] objevila hodnota NULL, INNER JOIN by záznam vynechal. Pokud chceme použít OUTER JOIN, musíme napsat LEFT JOIN nebo RIGHT JOIN, podle toho, jestli chceme povolit nulové hodnoty v první tabulce nebo v druhé (té připojované). Častější je LEFT JOIN, pokud by se tedy v tabulce [Zaci] ve sloupci [IdTrida] vyskysla hodnota NULL, spojení se provede a do všech sloupců připojované tabulky se nastaví hodnota NULL. Takže název třídy pro tento řádek bude také NULL. Nejčastěji se tedy používá buď samotné JOIN, nebo LEFT JOIN.
Spojování tabulek přehledně
| Spojení dvou tabulek na základě shody hodnot ve dvou sloupcích (přirozené spojení); přidá-li se podmínka – theta spojení | SELECT jméno_sloupce FROM název_tabulky1 INNER JOIN název_tabulky2 ON název_tabulky1.jméno_sloupce=název_tabulky2.jméno_sloupce; |
| Vnější spojení dvou tabulek zleva, všechny hodnoty z první tabulky + hodnoty, kde je shoda; kde není shoda, bude NULL | SELECT jméno_sloupce FROM název_tabulky1 LEFT JOIN název_tabulky2 ON název_tabulky1.jméno_sloupce=název_tabulky2.jméno_sloupce; |
| Vnější spojení dvou tabulek zprava, všechny hodnoty z druhé tabulky + hodnoty, kde je shoda; kde není shoda, bude NULL | SELECT jméno_sloupce FROM název_tabulky1 RIGHT JOIN název_tabulky2 ON název_tabulky1.jméno_sloupce=název_tabulky2.jméno_sloupce; |
| Vnější spojení dvou tabulek, všechny hodnoty z obou tabulek + hodnoty, kde je shoda; kde není shoda, bude NULL | SELECT jméno_sloupce FROM název_tabulky1 FULL OUTER JOIN název_tabulky2 ON název_tabulky1.jméno_sloupce=název_tabulky2.jméno_sloupce; |
| Sjednocení tabulek, stejné řádky jsou potlačeny (chcete-li vidět stejné řádky vícekrát, za UNION se přidá ALL) | SELECT jméno_sloupce FROM název_tabulky1 UNION SELECT jméno_sloupce FROM název_tabulky2; |
Editace záznamů UPDATE
Často potřebujeme nějaká data v tabulce změnit, například již zmiňovaná situace změny názvu třídy. Přišel totiž nový rok a z prvňáčků jsou druháci. Je tedy třeba změnit jejich názvy tříd. To obstará příkaz UPDATE.
UPDATE [Tridy] SET [Nazev] = '2.A' WHERE [IdTrida] = 1
Obecně tedy napíšeme UPDATE, dále název tabulky, pak slovo SET a přiřazení sloupec = hodnota (může jich být víc oddělených čárkou). Následuje podmínka, která jednoznačně určí, které záznamy se mají upravit. Pokud ji nezadáte, upraví se všechny!
Ze třídy 1.B se tedy má stát třída 2.B, ale zároveň jejich paní učitelka odešla do důchodu a vystřídal ji pan učitel. Musíme tedy upravit dvě hodnoty.
UPDATE [Tridy] SET [Nazev] = '2.B', [TridniUcitel] = 'Josef Lukeš' WHERE [IdTrida] = 2
Mazání záznamů DELETE
Někdy je třeba záznamy smazat, k tomu máme příkaz DELETE. Napíšeme DELETE FROM, dále název tabulky a pak podmínku, která řekne, které záznamy se mají smazat. Opět platí, že pokud ji nezadáme, smaže se vše!
DELETE FROM [Zaci] WHERE [IdZak] = 3
Další „čachry“ s databázemi
Kdyby databáze uměly jen toto, vyvíjely by se aplikace poměrně špatně. Vazby mezi daty bývají často velmi složité a není možné je popsat takto triviálními prostředky. Zmíním se tedy krátce o dalších prvcích, které může databáze obsahovat.
Pohledy (VIEW) slouží ke zjednodušení běžných SELECT příkazů. Pokud budu psát redakční systém, kde mám tabulku autorů, článků a kategorií, zcela jistě si udělám pohled, který mi vypíše články již spojené se jmény autorů a názvy kategorií. Pak napíšu jen SELECT * FROM ViewClanky, kde ViewClanky je název daného pohledu, a je to stejné, jako kdybych psal SELECT * FROM Clanky LEFT JOIN Autori … LEFT JOIN Kategorie … atd.
Uložené procedury (Stored Procedures) slouží k provedení více operací najednou. Je to víceméně totéž co procedury v běžných programovacích jazycích – dostanou nějaké parametry, provedou určité příkazy a ještě umí vrátit nějaká data (např. tabulku). U složitějších databází se často nepracuje přímo s tabulkami, ale každá tabulka má vytvořené procedury pro přidávání, opravy a mazání záznamů, kde se dají například kontrolovat oprávnění pro provedení akce a různé další funkce.
Triggery jsou jakési reakce na událost. Pokud například přidáme záznam do tabulky nebo jej smažeme či upravíme, můžeme naprogramovat trigger, který provede další akci (třeba odešle e-mail, i to databázové servery často umí).
Schémata slouží hlavně v obrovských a složitých databázích, kde máme hodně tabulek a je možné, že nastanou konflikty v pojmenováních. Můžeme tedy vytvořit schémata, která se zapisují před název tabulky, a díky tomu smečku tabulek rozdělit an několik logických celků.
Cvičení
C1 – základní příkazy teoreticky
C2 – vytvoření tabulky teoreticky
Založme si na zkoušku tabulku se zaměstnanci, která bude obsahovat údaje k pracovníkům, kde:
- ID_Zamestnanec – bude primární klič tabulky – jedinečný identifikátor číselného typu
- Jmeno, Prijmeni, Pozice, Oddeleni – bude typu VARCHAR, hodnota musí být vždy vyplněna (NOT NULL)
- FK_NadrizenyZamestnanec – cizí klíč na šéfa daného zaměstnance – uděláme formou self seferenced foreign key – pole s nadřízeným bude reference na primární klíč ID_Zamestnanec. Pole může být NULL, nejvýše postavení zaměstnanci nemají nadřízeného
- Zamestnan_Od, Zamestnan_Do – datumové pole. Zamestnan_Do může být NULL
- Je_Zamestnan – Identifikátor jestli je zaměstanec v současné době zaměstnán, nabává hodnoty 1,0. Nemůže být prázdné
Tabulku s výše nadeninovaným seznamem sloupců, datovými typy a definicemi založíme takto:
CREATE TABLE dbo.Zamestnanci ( ID_Zamestnanec INTEGER IDENTITY(1,1) PRIMARY KEY, Jmeno VARCHAR(255) NOT NULL, Prijmeni VARCHAR(255) NOT NULL, Pozice VARCHAR (255) NOT NULL, FK_NadrizenyZamestnanec INT NULL, Oddeleni VARCHAR (255) NOT NULL, Plat INTEGER NOT NULL, Zamestnan_Od DATE NOT NULL, Zamestnan_Do DATE NULL, Je_Zamestnan INT NOT NULL );
ALTER TABLE dbo.Zamestnanci ADD CONSTRAINT FK_SelfReference FOREIGN KEY (FK_NadrizenyZamestnanec) REFERENCES dbo.Zamestnanci (ID_Zamestnanec);
Vidíme, že skript má 2 části, pomocí příkazu jsme vytvořili tabulku a pomocí DDL příkazu ALTER TABLE přidáváme constraint typu cizí klíč.
C3 – vytvoření DB knih prakticky
C4 – výpis dat z tabulky
Pro výpis dat z tabulky slouží příkaz SELECT. Za něj zapíšeme názvy sloupců, které chceme vrátit, pak napíšeme FROM a název tabulky. Můžeme specifikovat setřídění či podmínku. Pokud chceme všechny sloupce, napíšeme hvězdičku.
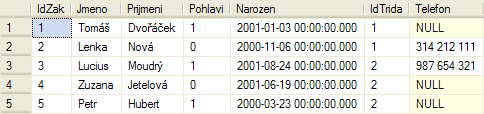
Výběr všech žáků
SELECT * FROM [Zaci]
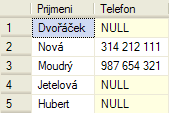
Vybrat jen příjmení a telefony
SELECT [Prijmeni], [Telefon] FROM [Zaci]
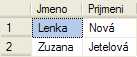
Vybrat jen dívky
SELECT [Jmeno], [Prijmeni] FROM [Zaci] WHERE [Pohlavi] = 0
Vybrat žáky narozené po 1. 1. 2001 a jen ze třídy 1.B
SELECT * FROM [Zaci] WHERE [Narozen] > 'January 1, 2001' AND [IdTrida] = 2

Vybrat jen chlapce a seřadit je podle příjmení
SELECT * FROM [Zaci] WHERE [Pohlavi] = 1 ORDER BY [Prijmeni]

Žáci, kteří nemají telefon, seřazení podle data narození sestupně
SELECT * FROM [Zaci] WHERE [Telefon] IS NULL ORDER BY [Narozen] DESC

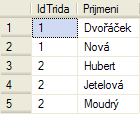
Žáci seřazení podle třídy a pak podle příjmení
SELECT [IdTrida], [Prijmeni] FROM [Zaci] ORDER BY [IdTrida], [Prijmeni]
C5 – návrh DB
Zdroje: